目录
| Folien | Chapter | Video | |
|---|---|---|---|
| Fundamentals | 01 | Chapter 1 | 1.1.1 - 1.1.7 |
| Embedded Systems | - | Appendix E.1 | 1.1.8 |
Fundamentals
Folien aca 01 / Chapter 1 / Video 1.1.1 - 1.1.7
重点是Performance 和 量化原理,其他是简单的定义。
Trends
Classes of Computers
-
Desktop
-
Server
-
Embedded Computer
distinguish 2 more classes:
-
Personal Mobile Devices
-
Warehouse-scale Computers
Computer Architect/Design
Determine the important attributes
Design a machine to
- maximize performance and energy efficiency
- stay within cost, power and availability constraints
Including:
- Instruction set design
- Functional organization (u-architecture)
- Logic design and implementation
- Assist marketing, sales, customers
- Validation and debug support
Computer Architecture
is the science and art of selecting and interconnecting hardware components to create computers that meet functional, performance and cost goals.
- Instruction set architecture
- Organization (micro architecture)
- Hardware (Detailed logic design and packaging tech.)
Trends in Power in IC
Issues:
- Get In: Bring Power to the Chip
- Get out: Remove Heat
Why: Battery Life, Power Consumption, Environment, Power Density
Performance
-
Time:
-
$Performance = \frac{1}{Execution Time}$
-
Increasing performance means decreasing execution time
Execution Time can be defined in different ways:
-
Wall-clock Time = response time = elapsed time
The latency to complete a task. Includes Everything: disk accesses, I/O, OS overhead, …
-
CPU Time *(when talking about the time of a program)
CPU computing time, not time waiting for I/O or other programs
- User CPU Time : CPU time spent in the program
- System CPU Time: CPU time spent in OS
-
-
-
Throughput / Rate = n jobs / second
multiprogrammed CPU works on other process when current process stalled for I/O. It does not improve the execution time of current process, but improve the throughput.
-
-
Availability: the percentage of time, a system is up and running
-
Scalability: the ability of a system to expand performance
-
Performance per Watt: the number of flops per watt of power as seen before
Benchmarks
a program used to evaluate performance.
Five types (in order of accuracy high to low):
- Real applications
- portability problems
- important activity has to be eliminated
- Modified (or scripted) applications
- enhance portability 增强可移植性 以便多平台运行
- forcus on particular aspect of system performance
- e.g. CUP-oriented benchmarks will remove I/O
- scripts to reproduce interactive behaviour
- Kernels
- small, key pieces from real programs (key = consume lots of Ex Time)
- best used to isolate the performance of certain features
- Toy benchmarks
- small, easy but not useful ti evaluate perf
- Synthetic benchmarks
- typical instruction mixes
- whetstone and dhrystone
Benchmark Suites
a collection of benchmarks that measure the performance with a variety of apps.
Most successful attempt tp create a standard: SPEC (focuses on CPU)
- Processor-intensive Benchmarks:
- SPEC SPU 2006
- Graphics-intensive Benchmarks
- SPECviewperf: OpenGL 3D rendering
- SPECapc: extensive use of graphics
- Server Benchmarks with significant I/O
- SPECSFS: serve
- SPECWeb: web
Embedded Benchmarks
Less developed than desktop (CPU+GPU) and server benchmarks. (嵌入式系统各不相同,各自设计各自的benchmark)
One attempt: EDN Embedded Microprocessor Benchmark Consortium (EEMBC)
Kernels and benchmarks that fall into 5 classes
- Automotive/industrial
- Consumer
- Networking
- Office automation
- Telecommunications
Summarizing Performance
- total execution time: summary from all programs in one Computer
- arithmetic mean: $\frac{1}{n}\sum_{i=1}^n{Time}_i$
if the programs are not run equally?
-
weightedexecution time: $\sum_{i=1}^n{Weight}_i \cdot {Time}_i$ -
normalizedexecution time (Used by SPEC):Normalize execution times to a reference machine and take average
SPECRatio= $\frac{Execution Time_{reference}}{Execution Time}$don’t use the arithmetic mean to average normalized execution time
lead to different results depending on the reference machine
use
geometric mean
Quantitatice Priciples
CPU Performance Equation
Cycle time : reciprocal of CPU frequency/Clock rate f Cycle time = rate$^{-1}$ (e.g. 1 GHz: 1 ns)
IC: Instruction count (or instruction path length) = number of instructions executed
CPI : cycles per instruction = Cycle count / IC
so CPU time = Cycle count for a program × Cycle time = IC × CPI × Cycle time
That means, CPU performance equally depends on
IC,CPIandfrequency.10% improvement in any of them leads to 10% overall improvement.
We can improve that in:
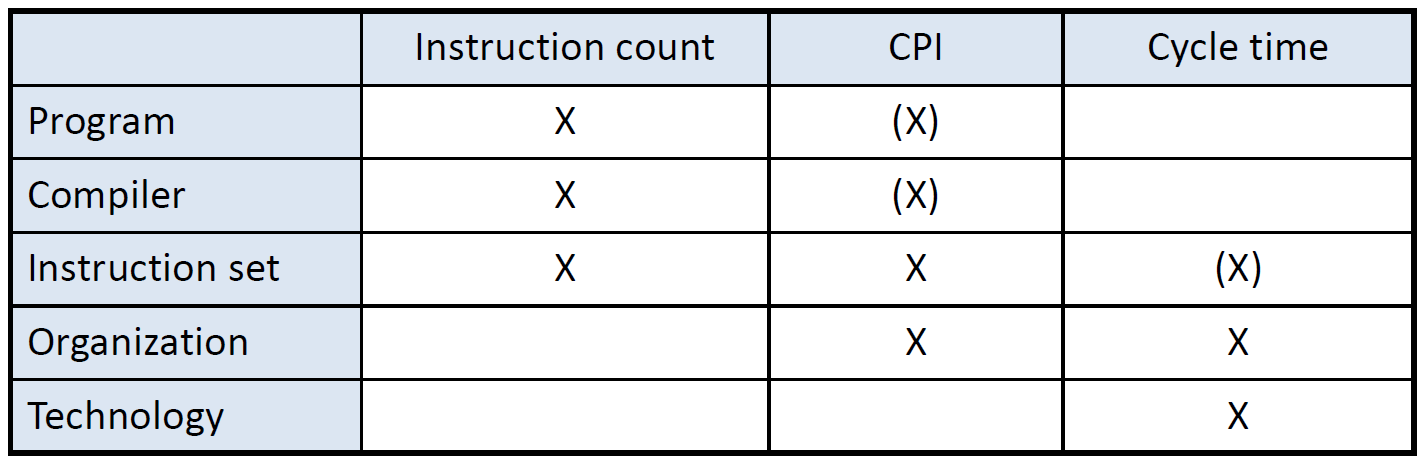
By designing CPU, it is useful to calculate the number of total CPU clock cycles as:
CPU clock cycles (Cycle count) = $\sum_{i=1}^{n}IC_i \times CPI_i$ (指令数 × 每条指令需要的周期数)
Sometimes we know how many cycles each instruction takes and the frequency of each instruction. The average CPI can be calculated as:
CPI = $\sum_{i=1}^{n}CPI_i\times Freq_{i}$
where
- $CPI_i$ is the average CPI for instruction i
- $Freq_{i} = IC_i / IC$ is the frequency of instruction i
即 知道每个Op的周期,知道每个Op的占比,但不知道每个Op有多少IC
Amdahls’ Law
to calculate the improvement of performance by using a enhancement E
speedup = $\frac{ExTime \quad without \quad E}{ExTime \quad with \quad E}$
if the enhancement E accelerates a fraction F of the whole task by a factor S. The new execution time can be calculated as:
$T_{new} = (1-F) \cdot T_{old} + F \cdot T_{old} / S$
The overall speedup is:
$Speedup = \frac{T_{old}}{T_{new}} = (1-F+\frac{F}{S})^{-1}$
最大speedup (即S趋向正无穷) 是 1-f 的倒数
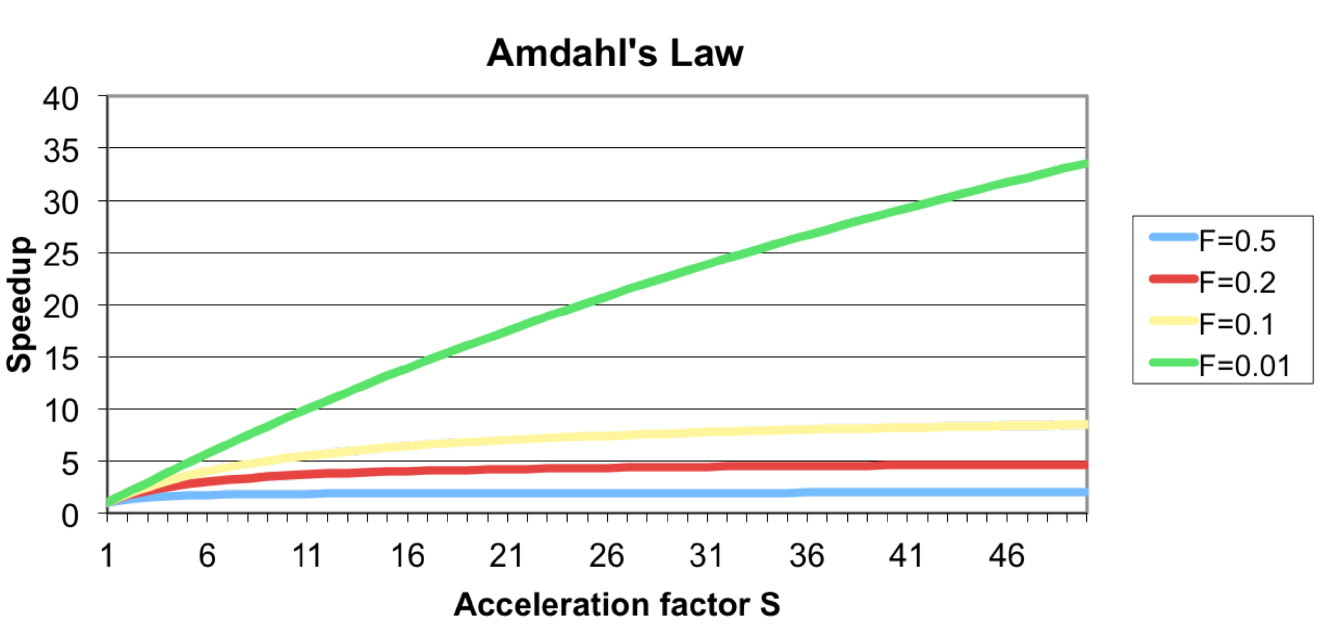
Implications:
Focus on the Common Case (优化大的部分很赚 80%快2倍 还是 20%快10倍)
Law of diminishing returns: optimizations will have less and less effects
Design Principles
to Make Processors Faster
- Take advantage of parallelism:next chapter
- Principle of locality:
- Programs spend 90% of their execution time in 10% of their code
- can predict with reasonable accuracy which instructions and data program will use in near future
- Make the common case fast
Sample Questions
-
The trend of the increment of single-core performance, Causes, Follow-up situation of semiconductor:
Trend: The 17-year hardware renaissance is over. Single-processor performance improvement has dropped to less 22% per year since 2003.
Causes:
6th Edition: The fundamental reason is that two characteristics of semiconductor processes that were true for decades no longer hold. 1.
Power density-Dennard scalingended around 2004 - led to using multiple efficient procesors or cores. 2. - ` the number of transistor ` -Moores' lawended - Q3..The combination of
■ transistors no longer getting much better because of the slowing of Moore’s Law and the end of Dinnard scaling,
■ the unchanging power budgets for microprocessors,
■ the replacement of the single power-hungry processor with several energyefficient processors, and
■ the limits to multiprocessing to achieve Amdahl’s Law
caused improvements in processor performance to slow down.
5th Edition: due to the twin hurdles of
maximum power dissipation of aircooled chipsand thelack of more instruction level parallelismto exploit efficiently.Follow-up: Intel canceled its high-performance uniprocessor projects and joined others in declaring that the road to higher performance would be via
multiple processorsper chip rather than via faster uniprocessors. -
three main classes of computers:
Desktop Computing (largest market), Serves, Embedded computer.
-
Moore’s Law:
Number of transistors that can be placed inexpensively on an integrated circuit doubles approximately every two years.
-
Benchmark:
a program used to evaluate performance.
Real Applications are the best choice of benchmarks.
SPEC: The Standard Performance Evaluation Corporation (SPEC) is one of the most successful attempts to create standardized benchmark application suites. There are now SPEC benchmarks to cover many application classes.
-
Normalized Execution Time:
why not arithmetic mean?
it can lead to different results depending on the reference machine.
eg.
A B A B A B Program P1 1 10 1.00 10.00 0.10 1.00 Program P2 1000 100 1.00 0.10 10.00 1.00 Arithmetic 1.00 5.05 5.05 1.00 Geometric 1.00 1.00 1.00 1.00 -
improve 75% of our application by a factor of 3 xor 50% by a factor of 10.
$Speedup_1 = ((1-0.75) + 0.75 / 3 ) ^ {-1} = 2$
$Speedup_2 = ((1-0.5) + 0.5 / 10 ) ^ {-1} = 1.818$
-
improve part of our application by a factor of 4 and want to achieve an overall speedup of 2. How large should the fraction be.
$ Speedup = 2 = ((1-F) + F / 4 ) ^ {-1} $
$F = 2/3$
-
In an application 50% instructions take 1 cycle, 20% take 2 cycles, 30% take 2.4 cycles on average. What is the average CPI? This application executes 1.6x10$^9$ instructions and the clock frequency is 3GHz. How much time does the program take?
$CPI = 50\% \times 1 + 20\% \times 2 + 30\% \times 2.4 = 1.62$
$IC = 1.6 \times 10^9 \qquad f =3 \times 10^9 Hz$
$T = IC \times CPI \times f^{-1} = 1.6 \times 10^9 \times 1.62 \times (3 \times 10^9)^{-1} = 0.864 s$
Embedded Systems (Intro.)
Folien none / Appendix E.1 / Video 1.1.8
Embedded Systems
computer system with dedicated function lodged in other devices (the boundary is hard to define.)
Characteristics and Requirements
- Execute 1 or few applications (designer optimize the system for that app or those apps)
- lower compatibility battiers (the software is sold together with the hardware)
- Real-time constraints (complete their tasks on time otherwise iy is considered a failure)
- Minimize cost
- Minimize power consumption (powered by batteries and no fans for cooling)
- Minimize memory usage (the memory can be a substantial portion of the system cost)
- Physical dimensions (fit in a small device)
- Interface with physical word
Real-Time Constraints
A real-time performance requirement is one where a segment of the application has an absolute maximum execution time that is allowed.
- Hard real-time system
- all deadlines are hard (the worst case execution time need to be shorter that the deadline)
- missed deadline = total system failure
- e.g. Airbag
- Soft real-time system
- some deadlines are soft (only the average execution time need to be shorter that the deadline)
- soft deadline may occasionally be missed
- e.g. Video Player
Implementation Alternatives
in order of performance power low to high, and also flexibility high to low
- General purpose processors (GPPs)
- e.g. ARM processor
- flexible
- may not meet the performance requirements of the applications
- Application-specific instruction set processors (ASIPs)
- a processor whose instruction set has been tailored to benefit a specific app
- commercial tools to design an ASIP: Synopsys ASIP Designer, Codasip codasip studio
- Reconfigurable hardwares - Field programmable gate arrays (FPGAs)
- can exploit all the parallelism in an app and therefore achieve higher performance
- can take a very long time
- Application-specific integrated circuits (ASICs)
- IC customized for a single particular use
- takes a long time and a high cost
- only cost-effective if many devices will be sold