目录
| Folien | Chapter | Video | |
|---|---|---|---|
| MIPS64 | 02 | Appendix A and K | 1.2.1 - 1.2.4 |
| Pipelining & Harzard | 03 | Appendix C.1 | 1.3.1 - 1.3.10 |
| Multicycle Operations & Harzard | 03 | Appendix C.5 | 1.4.1 - 1.4.2 |
| MIPS R4000 | 03 | Appendix C.6 | 1.4.3 |
| Scheduling | 04 | Chapter 3.2 | 1.4.4 - 1.4.7 |
MIPS64
Folien 02 / Appendix A and K / Video 1.2.1 - 1.2.4
- simple load-store instruction set
- Only load/store instructions access memory
- To process data, need to load it into register first
- designed for pipelining efficiency
- Fixed instruction set encoding
- efficient instruction set for compiler to target
Registers
- has 32 64-bit general-purpose registers (GPRs) R0 - R31
- R0 is a hardwired 0
- has 32 64-bit floating-point registers (FPRs) F0 - F31
- to hold a 32-bit single precision floating point or 64-bit double precision floating point
- when used as single precision float, half of FPR is unused
- few special registers
- hi and lo:
- eg. for multiply: n bit * n bit = 2n bit which can not be placed in a n bit register
- floating-point status register
- exception program counter
- hi and lo:
Data Types
-
Integer:
-
8-bit: bytes (char)
-
16-bit: half words (short, Unicode)
-
32-bit: words (only in mips)
-
64-bit: double words
-
32-bit to 64-bit:
to increase the amount of directly addressable memory
-
-
-
Operations process 64-bit integers
-
如果使用bytes等小于64位的integer,需要用zero extended或sign extended转换成64位integer
-
zero extended:
free positions are filled with zeros
-
sign extended:
a sign bit will be copied into the free position
-
-
-
Floating-point
- 32-bit single-precision (float)
- 64-bit double-precision (double)
Addressing Modes

-
Mode bit specifies:
-
Big Endian
-
Little Endian
-
图中为32bits整数
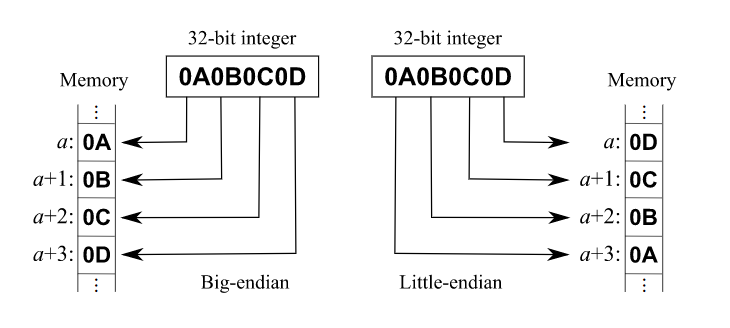
-
Instruction Formats
-
32 bits long
-
R type: <Register direct>
-
I type: <Immediate>
- sign extended
-
J type:
- 26 bits instruction address,地址是64位
- 怎么从26变成64?
- When a J-type instruction is executed, a full target address is formed by concatenating [1] the high order bits of the PC (the address of the instruction following the jump), the [2] 26 bits of the target field, and [3] 2 zero bits.
- [2] 26 bits of the target field
- [3] 2 zero bits:因为地址/指令地址是对齐的(4Bytes 32bits: 比如地址结尾是 …000 的后一条指令地址是 …100 , 000同时占用了001,010,011 四格) 最后2bits可以省略 (相当于除以4/右移2位)
- [1] high order bits of the PC: 指令只接受64位输入,也就是说28-63位的值由当前PC提供 (即 $(PC+4)_{63..28}$)
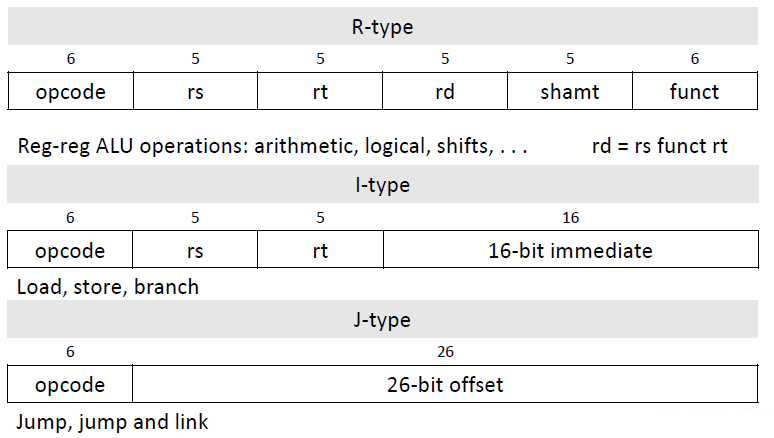
| MIPS64 | 长度 |
|---|---|
| 整数寄存器 | 64 bits |
| 浮点数寄存器 | 64 bits |
| 指令 | 32 bits |
| 指令opcode | 6 bits |
| 寄存器数量 | 32个 = 5 bits = 2的5次方: 1. 两种寄存器各32个,2.R/I指令的rs/rt/rd部分都是5位长的 |
| 地址 | 64 bits (一个寄存器能存下的长度) |
| * J指令地址部分 | 26 bits (32bits的指令-6bits的opcode) 但地址是64bits的, 1. 26位的地址补两个0变成28位(0-27),因为地址是4byte对齐的所以补两个0没关系 2. 28位的地址加上当前PC提供第28-63位,补充成64位(0-64) |
| 各种数据 | 8 bits - 64 bits |
| bytes / Char | 8 bits |
| half words / Short / Unicode | 16 bits |
| words | 32 bits |
| double words | 64 bits |
| single-precision floating-point / Float | 32 bits |
| double-precision floating-point / Double | 64 bits |
| 指令操作时处理的数据 | 64 bits (不足的需要补成64位长度 比如8bit的char在操作中会补充成64bit) |
Basic Code Optimization
- Eliminating redundant branches
- Eliminating induction variables
- Loop unrolling
Pipelining
Classical 5-Stage Pipeline
Folien 03 / Appendix C.1 / Video 1.3.1 - 1.3.10
- IF: Instruction fetch
- Fetch instruction using PC
- PC=PC+4 *(4×8=32 每条指令的长度)
- ID: Instruction decode
- decode
- read rs and rt fields in each instruction
- read IMM as sign extended 64bit Integer
- pass destination register rd and the next sequential PC to ID/EX pipeline register
- EX: Execute
- ALU
- MEM: Memory access
- Load + Store
- WB: Write-back cycle
- Write to register
Advantage
- all MIPS instructions same length
- few instruction formats, source registers always in same place
- only loads and stores access memory (MIPS is load/store architecture)
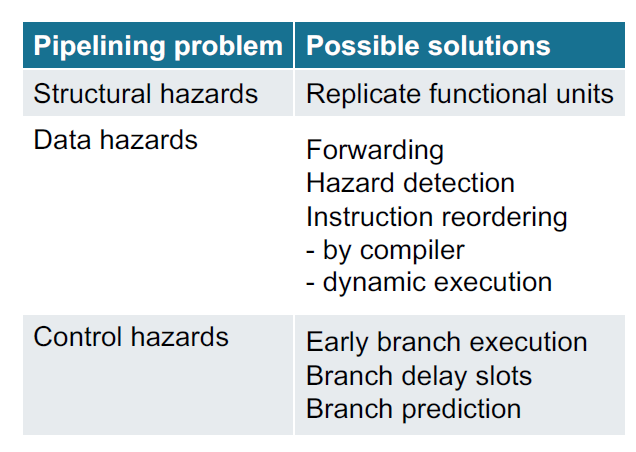
Hazard
- structural hazards: HW cannot support parallel execution of instructions
- 1 Mem w/ 1 read/write port
- IF,MEM can not be in a same Clock Cycle
- 1 Mem w/ 1 read/write port
- data hazards: instr. depends on result of prior instr. still in the pipeline
- Reg-Reg的矛盾 第一条指令的写Reg在CC5,第二条指令的读Reg在CC3
- Forwarding / Bypassing
- Using Pipeline Register (不需要写不需要读 第一条ALU计算好的直接进第二条ALU)
- write in the first half Clock Cycle, read in the second half Clock Cycle
- Forwarding / Bypassing
- **load use data hazard ** 在forwarding基础上 第一条指令load在MEM结束后读完CC4后半期,第二条指令需要ALU在CC4前半期
- Pipeline Interlock
- Bubble:空几个CC
- Scheduling
- Pipeline Interlock
- Reg-Reg的矛盾 第一条指令的写Reg在CC5,第二条指令的读Reg在CC3
- control(/branch) hazards: delay between fetching control flow instruction (branch or jump) and actual jump
- 分支指令在ALU比较完 决定是否跳转 找到跳转地址前有3个CC的空隙(penalty)
- Solution
- Determine Branch taken / not taken sooner
- Compute Branch Target address earlier
- MIPS solution
- Move branch condition evaluation to ID stage
- Calculate branch target address in ID stage
- Always execute instruction after the branch (branch delay slot)
- 这样做以后只有1个CC penalty 这个penalty 用一个指令来填满 这个指令一定会被运行(不能对之后有影响)
- From before branch instruction
- From target address: only valuable when branch taken
- From fall through: only valuable when branch not taken
- 都没有则用nop:dadd r0,r0,r0
Multicycle Operations
Folien 03 / Appendix C.5 / Video 1.4.1 - 1.4.2
Certain instructions (e.g., mul, div, floating-point operations) do not execute in one cycle
for example:
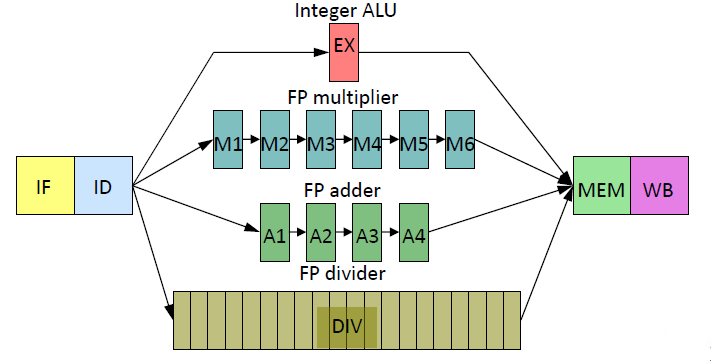
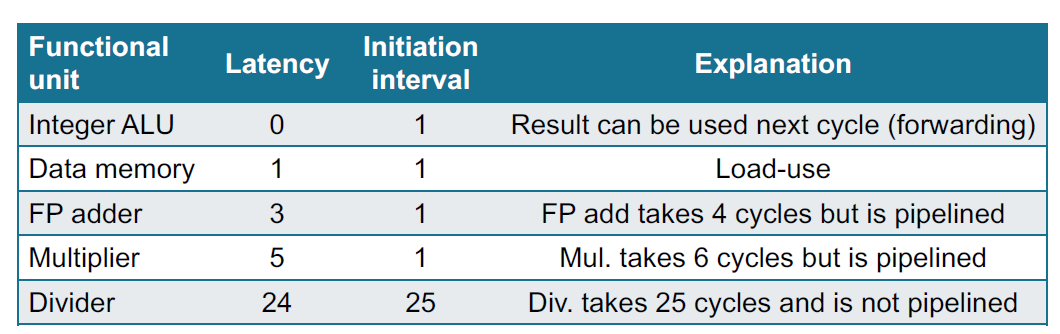

Hazard
- Structural Hazard
- Divider not pipelined (Division只能全部做完再开始下一个)
- stall and scheduling
- Varying latencies: write at the same cycle
- stall
- increase write ports
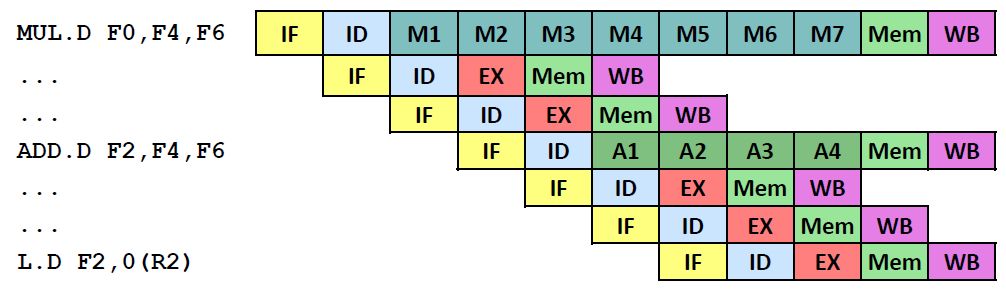
- Divider not pipelined (Division只能全部做完再开始下一个)
- WAW(write-after-write) Hazard
- do not always write back in order
- busy bit
- scheduling

- do not always write back in order
- instruction complete out of order
- RAW(read-after-write) Hazard
- this instruction depends on the instructions before
- stall

- this instruction depends on the instructions before
- Complexity of forwarding logic increases
MIPS R4000
Folien 03 / Appendix C.6 / Video 1.4.3
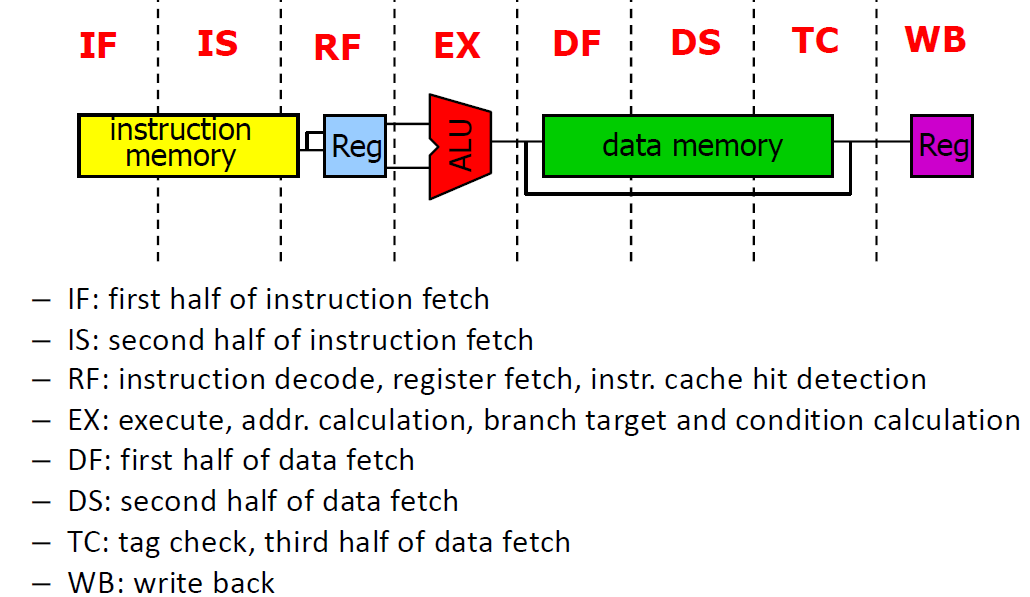
Scheduling
Folien 04 / Chapter 3.2 / Video 1.4.4 - 1.4.7
to solve the stall cycles in Multicycle Operations RAW Hazard
-
Swap the position of the instructions
to use unrelated instruction
- to fill the stall
- to fill the nop after branch instruction
-
Loop Unrolling

-
register renaming
- moving all loads before stores
- moving two SDs after DADDI and BNE
- using different registers
Compiler Steps
- Eliminate extra test and branch instructions and adjust loop termination and iteration code
- Determine that it is possible to move S.D after DADDI and BNE, and find amount to adjust S.D offset
- Determine that loop unrolling would be useful by finding that loop iterations were independent
- Rename registers to avoid name dependencies
- Determine loads and stores in unrolled loop can be interchanged by observing that loads and stores from different iterations are independent
- requires analyzing memory addresses and finding that they do not refer to the same address.
- Schedule the code, preserving any dependences needed to yield same result as original code
Advantages and Disadvantages
+improves potential for instruction scheduling
+reduces loop overhead
-increases code size
-shortfall in registers (register pressure)